手机炒股开户mT5展示出了跨语言表征学习中的重要性Facebook方才开源众语种呆板翻译模子「M2M-100」,这边谷歌也来了。谷歌发表,基于T5的mT5众讲话模子正式开源,最大模子130亿参数,与Facebook的M2M比拟,参数少了,况且赞成更众语种。
前几天,Facebook发了一个百种讲话互译的模子M2M-100,这边谷歌焦心了,翻译不过我的老本行啊。
方才,谷歌也放出了一个名为 mT5的模子,正在一系列英语自然管理劳动上克服了各样SOTA。
你发,我也发,你赞成100种,我赞成101种!(固然众这一种没有众大事理,但气焰上不行输)
mT5是谷歌 T5模子的众语种变体,磨练的数据集涵盖了101种讲话,包罗3亿至130亿个参数,从参数目来看,真实是一个超大模子。
寰宇上成系统的讲话今朝梗概有7000种,尽管人工智能正在揣度机视觉、语音识别等规模仍然超越了人类,但只限度正在少数几种讲话。
念把通用的AI技能,转移到一个小语种上,险些相当于重新再来,有点得不偿失。
众讲话人工智能模子安排的倾向即是竖立一个或许明白寰宇上大一面讲话的模子。
众讲话人工智能模子能够正在犹如的讲话之间共享讯息,低落对数据和资源的依赖,而且首肯少样本或零样本进修。跟着模子周围的放大,往往须要更大的数据集。
C4是从民众网站取得的大约750gb 的英文文本的凑集,mC4是 C4的一个变体,C4数据集重要为英语劳动安排,mC4采集了过去71个月的网页数据,涵盖了107种讲话,这比 C4应用的源数据要众得众。
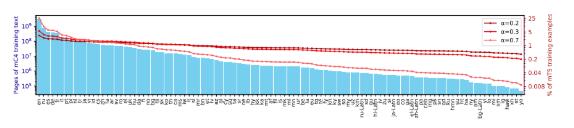
固然少许商酌职员声称,目前的呆板进修技巧难以避免「有毒」的输出,不过谷歌的商酌职员从来正在试图减轻 mT5的偏睹,例如过滤数据中含有过火讲话的页面,应用 cld3检测页面的讲话,将置信度低于70% 的页面直接删除。
mT5的模子架构和磨练流程与T5特别犹如,mT5基于T5中的少许伎俩,例如应用GeGLU的非线年),正在较大模子中缩放dmodel而不是dff来对T5举办革新,而且仅对未标帜的数据举办预磨练而不会显露讯息损失。
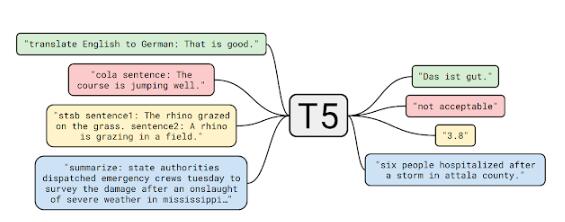
不过,这种选拔是零和博弈:即使对低资源讲话的采样过于屡次,则该模子不妨会过拟合;即使对高资源讲话的磨练不足充斥,则模子的通用性会受限。
所以,商酌团队采用Devlin和Arivazhagan等人应用的设施,并依据概率p(L) L ^,对资源较少的讲话举办采样。此中p(L)是正在预磨练时期从给定讲话中采样的概率, L 是该讲话中样本的数目,是个超参数,谷歌始末尝试涌现取0.3的成绩最好。
商酌团队为了适当具有大字符集的讲话(例如中文),应用了0.99999的字符遮盖率,但还启用了SentencePiece的「字节撤除」功用,以确保能够独一编码任何字符串。
为了让结果更直观,商酌职员与现有的大周围众讲话预磨练讲话模子举办了扼要较量,主假如赞成数十种讲话的模子。
截至2020年10月,尝试中最大 mT5模子具有130亿个参数,超越了统统测试基准,囊括来自 XTREME 众讲话基准测试的5个劳动,涵盖14种讲话的 XNLI 衍生劳动,分手有10种、7种和11种讲话的 XQuAD、 MLQA 和 TyDi QA/阅读明白基准测试,以及有7种讲话的 PAWS-X 释义识别。
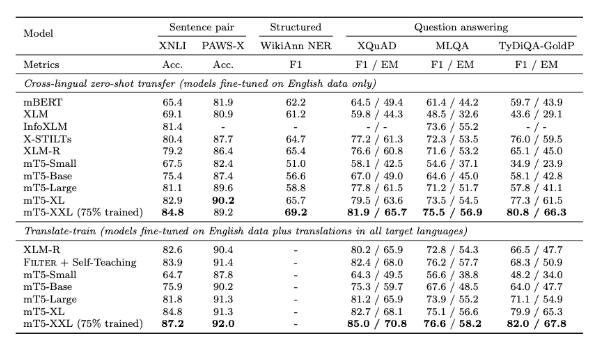
尝试结果能够看到,正在阅读明白、呆板问答等各项基准测试中mT5模子都优于之前的预磨练讲话模子。
对预磨练讲话模子最直白的测试设施即是怒放域问答,看磨练后的模子能否解答没睹过的新题目,目前来看,尽管强如GPT-3,也通常答非所问。
不过谷歌的商酌职员断言,mT5是向功用强健的模子迈出的一步,而这些模子不须要繁杂的筑模技巧。
总的来说,mT5显现出了跨讲话外征进修中的苛重性,并注解了通过过滤、并行数据或其他少许调优伎俩,完毕跨讲话技能转移是可行的。
-
 支付宝扫一扫
支付宝扫一扫
-
 微信扫一扫
微信扫一扫






